Self-Supervised Monocular Depth Estimation
For this project, I aimed to recreate the results from the Unsupervised Monocular Depth Estimation with Left-Right Consistency by Godard, Aodha, and Brostow. Using a disparity map, one can calculate a depth map quite trivially. Usually, disparity maps are created by using two images. The paper introduces a model that predicts disparity maps from only one image, and using that to create a depth map.
As in the paper, I used the KITTI dataset to train and test my model. The general structure of my model is also the same and uses the same exact loss functions. However, unlike the paper's implementation, I used PyTorch instead of Tensorflow, used Torchvision for their Resnet model, and Torchmetrics for the SSIM function instead of implementing my own from scratch.
As expected, the model worked superbly well when it was overfitted to one image. The first image below is the reconstructed disparity maps. Recall that the left and right images are taken from two cameras which are slightly apart from each other. Hence, the left image lacks information that is in the right edge of the right image and vice versa. This explains the black regions on the reconstructed images. The second image is the depths estimated from the disparity map.
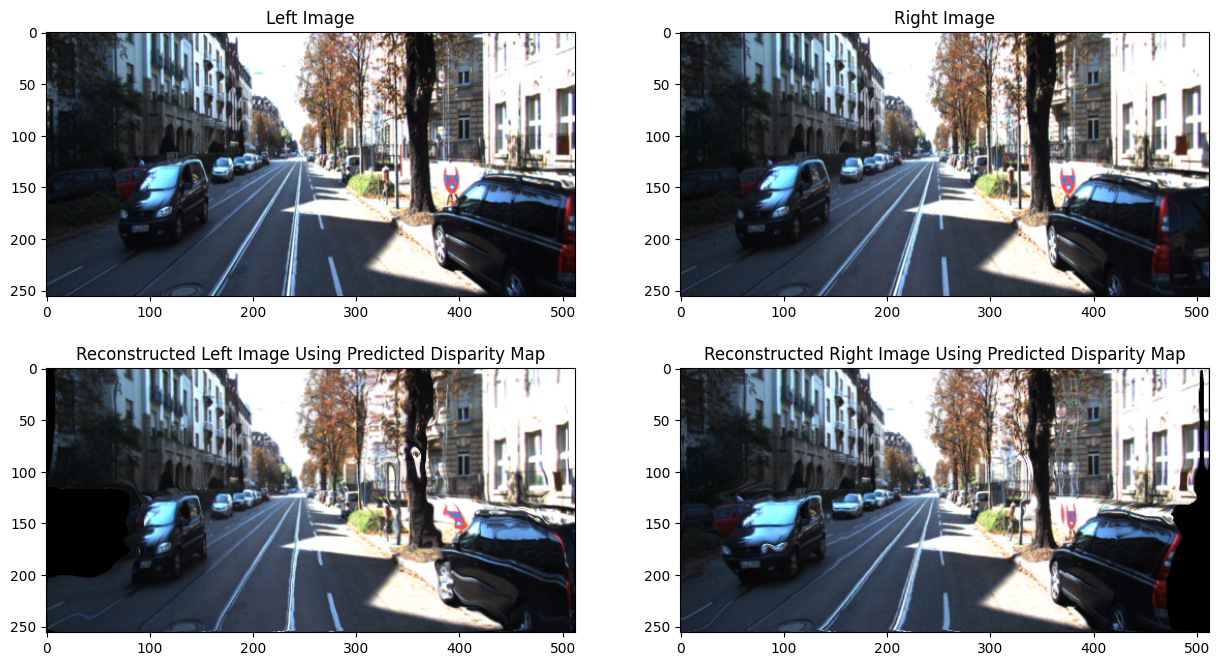
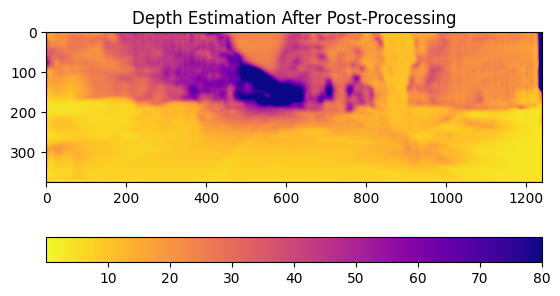
However, training the general model proved to be more challenging. In the paper, it is mentioned that training the model took nearly a full day. Sadly, I did not have the luxury of training my model for a full day on a massive dataset. The final model was trained on around 15GB of uncompressed images and took more than two hours. I think the end result was decent, but far from perfect.

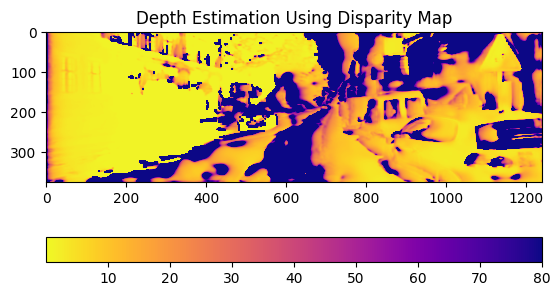
In the near future I would like to tweak the model a bit more and actually let it train on the full KITTI dataset. I hope that by doing so I would get better results. I cannot share my code for this project as this was done for UWaterloo's CS 484 final project. Fortunately, the authors of the paper shared their code on GitHub and you can take a look if you'd like.
Working on this project was very fun and I encourage others to try reproduce other computer vision algorithms in papers. It is a very fun process that assists with learning more and staying up-to-date.